

ちゆりです。競馬の予想をするにあたって参考にするのはやっぱり過去のデータですよね。
ということで、今回は競馬データ分析のためのデータをプログラミングで簡単に収集していきましょう。
プログラミング言語は今流行りのpython。そして僕の好きなpython。
サクッと作れるのでpythonでスクレイピングを行ってみたです。どうぞ
ちなみにココナラでデータの販売も行っています。
競馬の過去データ(2020年)1年分を提供します 競馬AI作成のためスクレイピングでデータ収集を行っていますpythonでデータ収集
まずは、スクレイピングでどのようなデータを取得するかを決めておきます。
- データはnetkeiba.comから取得してきます。
- 今回は順位、馬名、人気、枠、コース、距離を取得してみます。
- 取得したデータはCSV形式で出力します。
pythonでコードを書いてみよう
ざっと僕の書いたコードは以下です。
#スクレイピングに必要なモジュール
import requests
from bs4 import BeautifulSoup
#モジュールインポート
import sitelist
import time #sleep用
import sys #エラー検知用
import re #正規表現
import csv #csv操作
import numpy #csv操作
with open('result.csv', 'a', encoding="utf_8_sig") as csv_file:
fieldnames = ['result', 'Rank', 'Waku', 'Horse_Name', 'Course', 'Distance', 'Ninki']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for scraping_sitename in sitelist.SITE_URL:
#攻撃とみなされないように時間を置く
time.sleep(3)
try:
# スクレイピング対象の URL にリクエストを送り HTML を取得する
res = requests.get(scraping_sitename)
res.raise_for_status() #URLが正しくない場合,例外を発生させる
# レスポンスの HTML から BeautifulSoup オブジェクトを作る
soup = BeautifulSoup(res.content, 'html.parser')
# title タグの文字列を取得する
title_text = soup.find('title').get_text()
print(title_text)
#順位のリスト作成
Ranks = soup.find_all('div', class_='Rank')
Ranks_list = []
for Rank in Ranks:
Rank = Rank.get_text()
#リスト作成
Ranks_list.append(Rank)
print(Ranks_list) #debug
#馬名取得
Horse_Names = soup.find_all('span', class_='Horse_Name')
Horse_Names_list = []
for Horse_Name in Horse_Names:
#馬名のみ取得(lstrip()先頭の空白削除,rstrip()改行削除)
Horse_Name = Horse_Name.get_text().lstrip().rstrip('\n')
#リスト作成
Horse_Names_list.append(Horse_Name)
print(Horse_Names_list) #debug
#人気取得
Ninkis = soup.find_all('span', class_='OddsPeople')
Ninkis_list = []
for Ninki in Ninkis:
Ninki = Ninki.get_text()
#リスト作成
Ninkis_list.append(Ninki)
print(Ninkis_list) #debug
#枠取得
Wakus = soup.find_all('td', class_=re.compile("Num Waku"))
Wakus_list = []
for Waku in Wakus:
Waku = Waku.get_text().replace('\n','')
#リスト作成
Wakus_list.append(Waku)
print(Wakus_list)
#コース,距離取得
Distance_Course = soup.find_all('span')
Distance_Course = re.search(r'.[0-9]+m', str(Distance_Course))
Course = Distance_Course.group()[0]
Distance = re.sub("\\D", "", Distance_Course.group())
print(Course) #debug
print(Distance) #debug
with open('result.csv', 'a', encoding="utf_8_sig") as csv_file:
fieldnames = ['result', 'Rank', 'Waku', 'Horse_Name', 'Course', 'Distance', 'Ninki']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
#writer.writeheader()
#順位-馬名-人気のリスト作成(CSVへ書き込み)
for Rank_list, Waku_list, Horse_Name_list, Ninki_list in zip(Ranks_list, Wakus_list, Horse_Names_list, Ninkis_list):
#3位以内に入ったなら正解ラベル(result = 1)を振る
if Rank_list == "1" or Rank_list == "2" or Rank_list == "3":
result = 1
else:
result = 0
print(result, Rank_list, Waku_list, Horse_Name_list, Course, Distance, Ninki_list)
writer.writerow({'result': result, 'Rank': Rank_list, 'Waku': Waku_list, 'Horse_Name': Horse_Name_list, 'Course': Course, 'Distance': Distance, 'Ninki': Ninki_list})
except:
print(sys.exc_info())
print("サイト取得エラー")
ファイル構成とサイトリスト作成
準備として、ファイル構成は以下のように2ファイル準備しておきます
scrapingdir
├ scraping.py
└ sitelist.py別ファイルsitelist.pyにて取得したいURLのテーブルを作成しておきます。
ここのURLを増やすことで取得するデータを増やすことが可能です。
SITE_URL = [
"https://race.netkeiba.com/race/result.html?race_id=202006030601",
"https://race.netkeiba.com/race/result.html?race_id=202006030602",
"https://race.netkeiba.com/race/result.html?race_id=202006030603",
"https://race.netkeiba.com/race/result.html?race_id=202006030604",
"https://race.netkeiba.com/race/result.html?race_id=202006030605",
]ちなみにnetkeiba.comの以下のページのURLをSITE_URLに登録しておいてください。
(netkeiba.comのヘッダーのレース>>開催レース一覧から日付とレースを選択>>結果・払戻タブ
で表示されるURLを登録しましょう。)
beautifulsoupでスクレイピング
今回はpythonのスクレイピングライブラリの定番beautifulsoupを使っています。
beautifulsoupの詳しい使い方は書籍がおすすめ。
今回のスクレイピングのコードはこの書籍から学びました。

pythonを使ってスクレイピングでデータ収集をするならこの書籍はおすすめです。プログラミング界隈でド定番の参考書オライリーからの出版なので非常にタメになる。
スクレイピングデータ結果
上記のpythonを動かすと.csvファイルが作成されます。
Excelアプリで起動すればソートやフィルターなどをかけデータ分析にうまく使えそうですね。
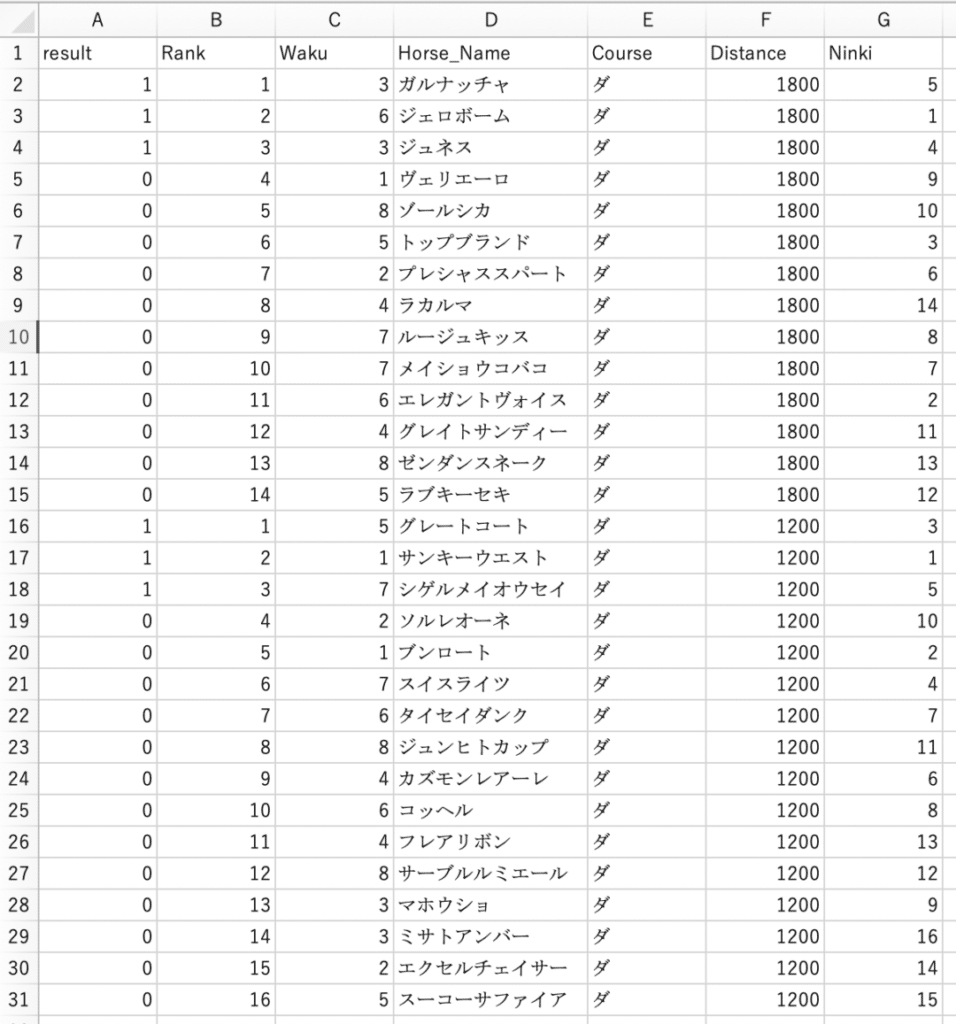
今回はデータ分析を行いやすいように、3位以内の場合は、resultの値を1にしています。
これで、フィルターをかける際にはresult=1で簡単に馬券に絡んだ馬を絞ることができます。
データ分析の結果と考察は過去の記事からどうぞ。

こんな感じで競馬のデータ分析のためのデータを収集してみました。
めんどくさいことはプログラミングに任せてしまいましょう。今後は分析まで自動化してみたいのですが、なかなかハードルは高めです。TensorFlow学習中...。競馬記事ファンのためにもぼちぼち更新していきますね。
スクレイピングを学んでいきたい方におすすめの本と動画を紹介しています。

ばいちゃ

コメント